The silent ticking of your hard drive might be a prelude to data loss. A failing hard drive can bring your digital world to a screeching halt, resulting in lost files, system crashes, and significant frustration. Fortunately, proactive diagnosis can often prevent catastrophic failure. This guide Artikels three crucial tests to assess your hard drive’s health and identify potential problems before they escalate into a major data disaster. By understanding these methods, you can take control of your data’s security and ensure the longevity of your system.
We’ll explore the use of SMART attributes to analyze underlying health indicators, delve into performance benchmarks to detect subtle degradation, and finally, examine the importance of a physical inspection. Each method provides a unique perspective on the overall health of your hard drive, allowing for a comprehensive assessment of its condition.
SMART Attributes and Hard Drive Health

Self-Monitoring, Analysis and Reporting Technology (SMART) attributes provide crucial insights into the health of a hard drive. By monitoring these attributes, users and system administrators can proactively identify potential issues and prevent data loss. Understanding the normal ranges and thresholds for these attributes is key to effective hard drive maintenance.
SMART attributes are numerical values that represent various aspects of a hard drive’s performance and reliability. Changes in these values, particularly exceeding predefined warning or critical thresholds, can signal impending failure. Regular monitoring of SMART attributes allows for early detection of problems, enabling preventative measures such as data backups or hard drive replacement before catastrophic failure occurs.
Relevant SMART Attributes and Their Thresholds
Several SMART attributes are particularly important indicators of potential hard drive failure. The following table Artikels some key attributes, their typical normal ranges, warning thresholds, and critical thresholds. Note that these values can vary slightly depending on the hard drive manufacturer and model. It is crucial to consult the manufacturer’s specifications for precise values.
| Attribute Name | Normal Value Range | Warning Threshold | Critical Threshold |
|---|---|---|---|
| Reallocated Sector Count | 0 | 1 | 5 or more |
| Current Pending Sector Count | 0 | 1 | 5 or more |
| Uncorrectable Sector Count | 0 | 1 | 1 or more |
| Spin-Up Time | Within manufacturer’s specifications (e.g., under 10 seconds) | 10-20 seconds | Above 20 seconds |
| Power-On Hours | N/A (not a failure indicator in itself) | N/A | N/A |
| Temperature | Below 45°C (113°F) | 50°C (122°F) | 60°C (140°F) |
Interpreting Changes in SMART Attributes
Changes in specific SMART attributes often indicate potential problems. For example, a rising “Reallocated Sector Count” indicates that the hard drive is experiencing bad sectors that have been remapped to spare sectors. While this is a mechanism to mitigate data loss, a consistently increasing count suggests a growing number of failing sectors, warranting attention. Similarly, a non-zero “Current Pending Sector Count” suggests the presence of sectors that are about to fail and need remapping. A rising “Uncorrectable Sector Count” is a serious warning sign, as it indicates sectors that could not be remapped and are likely causing data corruption.
Consider a scenario where a user observes a steady increase in the Reallocated Sector Count from 0 to 3 over a few weeks. This indicates that the drive is experiencing an increasing number of bad sectors. While the drive might still function, this is a clear warning sign to back up important data and consider replacing the drive to prevent potential data loss in the near future. Similarly, a sudden jump in the Uncorrectable Sector Count, even from 0 to 1, is a critical indicator that immediate action is required.
Interpreting SMART Data for Proactive Issue Identification
Regularly monitoring SMART attributes is crucial for proactive hard drive maintenance. Many operating systems and third-party utilities provide tools to access and interpret SMART data. These tools often display SMART attributes graphically, making it easy to identify trends and potential issues. Setting up alerts for specific threshold crossings can further enhance proactive identification. For example, configuring an alert when the Reallocated Sector Count exceeds 1 allows for early intervention before the count reaches a critical level. By regularly reviewing SMART data and responding appropriately to warning signs, users can significantly reduce the risk of hard drive failure and data loss.
Performance Benchmarks and Degradation Analysis
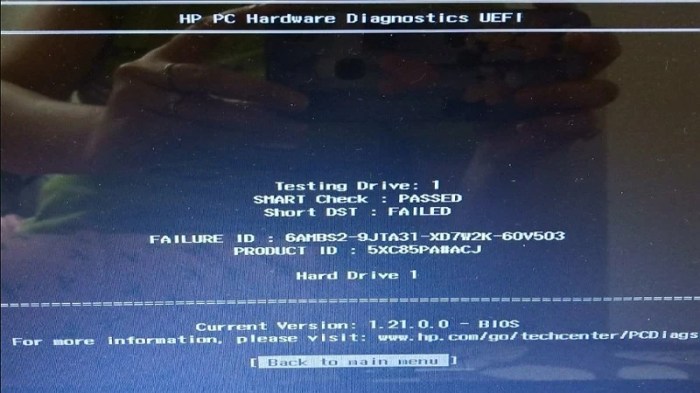
Analyzing a hard drive’s performance is crucial for detecting potential failures before they lead to data loss. Performance benchmarks provide objective measurements that can reveal subtle changes indicative of underlying problems, often preceding the appearance of more obvious symptoms like SMART attribute errors. Consistent monitoring and comparison against baseline performance values are key to early detection.
Performance benchmarks offer a quantifiable way to assess hard drive health, supplementing the information provided by SMART attributes. By tracking these metrics over time, we can identify trends and deviations that suggest problems. While SMART attributes focus on the physical health of the drive, performance benchmarks assess its operational efficiency. A combination of both provides a more comprehensive picture of the drive’s condition.
Common Performance Benchmarks and Their Significance
Several common benchmarks effectively measure hard drive performance. Significant deviations from established baseline values, especially consistent negative trends, often signal impending failure.
- Sequential Read/Write Speed: This measures the speed at which the drive reads or writes data sequentially (in a continuous stream). A significant drop in sequential read/write speeds, especially for large files, may indicate head alignment issues, media degradation, or controller problems. For example, a consistent decrease of 20% or more from the initial baseline speed warrants investigation.
- Random Read/Write Speed: This measures the speed of accessing data randomly scattered across the disk. A significant decrease in random read/write speeds often points to problems with the drive’s internal caching mechanism, head positioning, or overall drive health. A 30% drop in these speeds compared to the initial baseline performance should raise concern.
- Access Time: This measures the time it takes for the read/write head to locate specific data on the disk. Increased access time often indicates problems with the drive’s motor, head positioning mechanism, or platter surface. A persistent increase of 50% or more from the initial value can indicate significant problems.
- I/O Operations Per Second (IOPS): This measures the number of input/output operations the drive can perform per second. Low IOPS, particularly during heavy usage, suggests problems with data transfer efficiency, potentially related to controller issues, cache performance, or even failing sectors.
Reliability of Different Performance Metrics
The reliability of various performance metrics in detecting hard drive failures varies. While all metrics can provide valuable insights, some are more sensitive indicators than others. Sequential read/write speeds are generally less sensitive to minor issues than random access times or IOPS. A consistent decline in multiple metrics, particularly those measuring random access, strongly suggests a serious problem. Furthermore, comparing these metrics to manufacturer-specified speeds provides a useful reference point.
Hypothetical Scenario of Performance Degradation
Imagine a server hard drive consistently used for database operations. Initially, the drive shows excellent performance, with sequential read speeds around 150 MB/s and random read IOPS around 100 IOPS. Over six months, however, the random read IOPS steadily decrease to 60 IOPS, accompanied by a gradual increase in access time from 8ms to 15ms. Sequential read speeds also drop to 110 MB/s. This pattern strongly suggests degrading performance, potentially due to failing sectors or wear and tear on the drive’s components. The implications are significant, as this could lead to database query slowdowns, application unresponsiveness, and eventual data loss if the drive fails completely. Immediate replacement is recommended to prevent critical data loss and system downtime.
Physical Examination and Diagnostic Tools
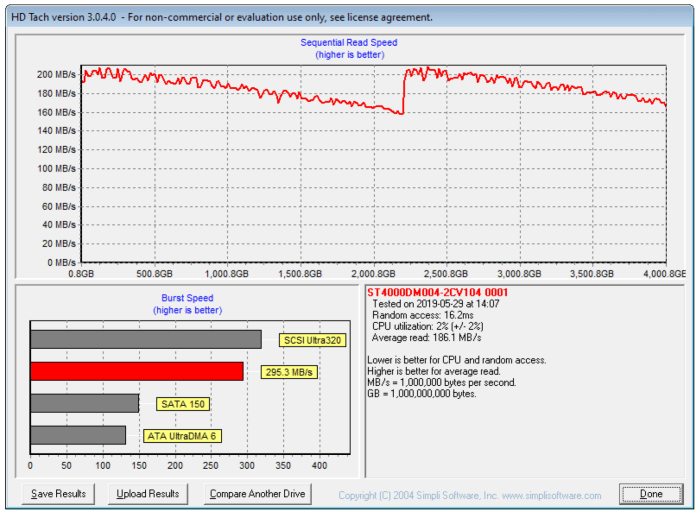
A thorough physical examination, coupled with the use of specialized diagnostic tools, can provide valuable insights into the health of a hard drive, complementing the data obtained from SMART attributes and performance benchmarks. These methods offer a more direct assessment of potential physical problems that might not be readily apparent through software analysis alone. This approach is crucial for identifying mechanical failures or damage that could lead to data loss.
Careful observation and the right tools can significantly improve the accuracy of diagnosis and inform decisions about data recovery or drive replacement.
Physical Inspection Procedure
A systematic visual and auditory inspection can reveal signs of impending failure or existing damage. The following steps should be followed in a controlled environment, preferably with the hard drive disconnected from power.
- Visual Inspection: Examine the hard drive casing for any signs of physical damage, such as dents, cracks, or warping. Look for any unusual discoloration or signs of leakage.
- Auditory Inspection: Listen carefully for unusual noises while the drive is operating (if possible, in a quiet environment). Clicking, grinding, or whirring sounds are often indicative of mechanical problems.
- Temperature Check (Indirect): Feel the hard drive casing for excessive heat. While a slightly warm drive is normal, significant heat generation could point to internal issues. Avoid touching the drive while it is operating.
- Connector Inspection: Carefully inspect the data and power connectors for any signs of damage, bending, or corrosion.
- Documentation: Record all observations, including the specific sounds heard, the location of any physical damage, and the temperature (if assessed).
Diagnostic Tools
Professional-grade diagnostic tools offer a more in-depth analysis of hard drive health than SMART data alone. These tools can detect subtle errors and predict potential failures more accurately.
| Tool Name | Functionality | Advantages | Limitations |
|---|---|---|---|
| DataLife Engine | Performs low-level surface scans, identifies bad sectors, and assesses overall drive health. | Comprehensive analysis, detects subtle errors, provides detailed reports. | Can be time-consuming, requires specialized knowledge to interpret results. |
| MHDD | Low-level hard drive diagnostics, surface scan, bad sector remapping. | Powerful, capable of recovering data from severely damaged drives, free to use. | Steep learning curve, requires advanced technical knowledge. |
| CrystalDiskInfo | Monitors SMART attributes, provides detailed information on drive health, user-friendly interface. | Easy to use, provides a clear overview of drive health, free to use. | Limited diagnostic capabilities compared to low-level tools. |
| SeaTools | Comprehensive diagnostic suite for Seagate and Samsung drives, includes surface scans and advanced tests. | Manufacturer-specific, often includes advanced features and support. | Limited compatibility with non-supported drive brands. |
Diagnostic Scan Interpretation
Interpreting the results of a diagnostic scan requires careful attention to detail. Error codes and warnings provide crucial clues about the drive’s condition. For example, a high number of bad sectors might indicate a failing hard drive, requiring immediate data backup and potential replacement. Specific error codes vary by tool, but generally, they will indicate issues such as read/write errors, head alignment problems, or controller failures. A detailed understanding of the specific error codes generated by the diagnostic tool is essential for accurate interpretation.
For instance, a consistent stream of “uncorrectable read errors” during a surface scan suggests significant media degradation, while repeated “seek error” messages could indicate a problem with the drive’s actuator arm. These errors, when combined with physical inspection findings, can help paint a complete picture of the drive’s health and inform the necessary actions, such as data recovery or drive replacement.
Outcome Summary

Regularly monitoring your hard drive’s health is crucial for data preservation. The three tests discussed—analyzing SMART attributes, benchmarking performance, and conducting a physical examination—offer a layered approach to early detection of potential failures. While no single test provides absolute certainty, a combined assessment offers a strong indication of your hard drive’s well-being. By proactively identifying and addressing issues, you can significantly reduce the risk of data loss and ensure the continued smooth operation of your system. Remember, prevention is always better than cure when it comes to protecting your valuable data.